LLM-as-a-judge for Knockout Evaluation
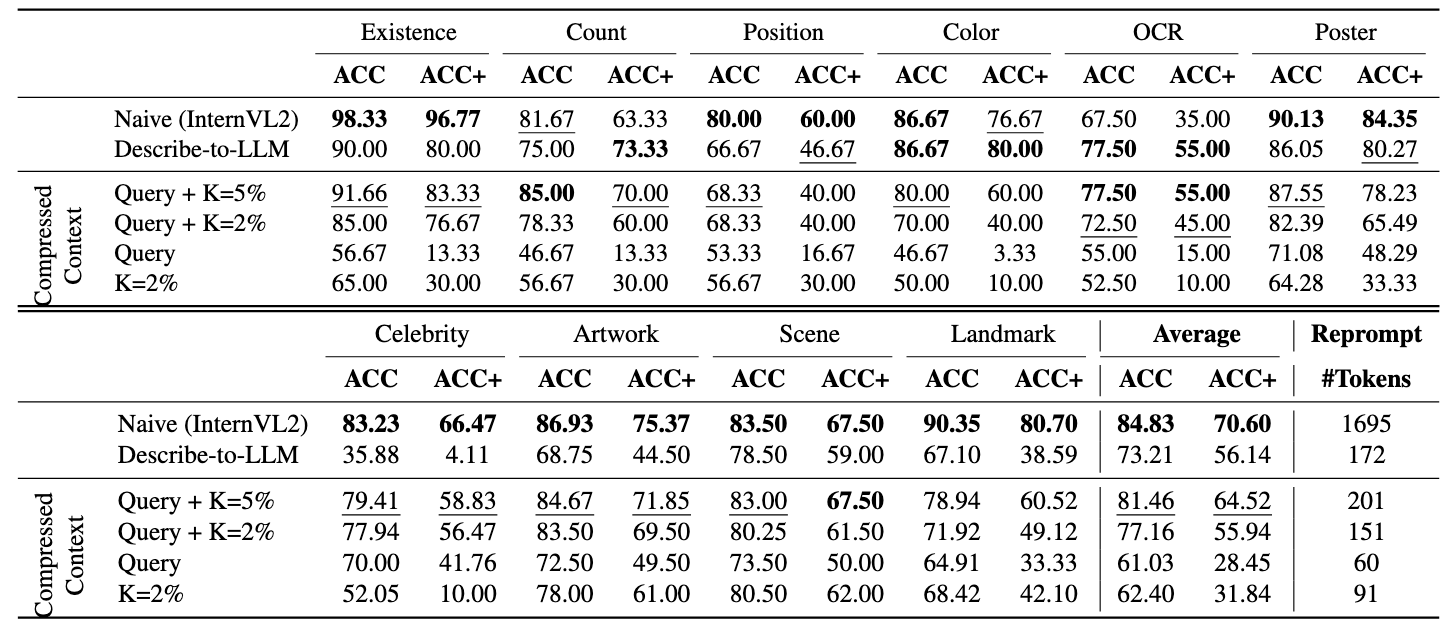
Automatically counting the number of identified or hallucinated objects in free-text paragraphs is challenging.
Therefore, we propose the LLM-as-a-judge evaluation protocol, which allows us to automatically assess object identification and hallucinated objects in generated responses under different knockout configurations.
Analyzing Visual Information Flow in Vision-Language Models
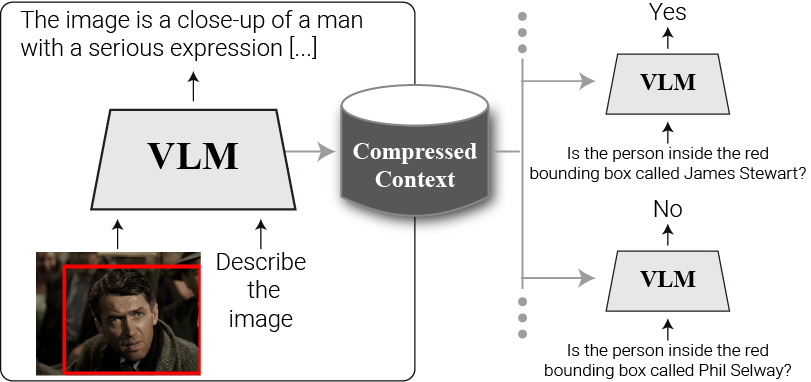
The figure below illustrates the flow of visual information in Vision-Language Models (VLMs) through an attention knockout analysis:
- (a) Baseline (No Knockout): The VLM employs only causal masking, allowing query and generated tokens to access image tokens.
-
To analyze the role of visual information flow, three attention knockout strategies were employed:
- (b) Image-to-generated knockout: Image tokens influence generated tokens only indirectly via query tokens.
- (c) Image-to-query knockout: Query tokens are prevented from accessing image information, isolating them from the visual context.
- (d) Image-to-others knockout: Image tokens are blocked from attending to all other tokens.
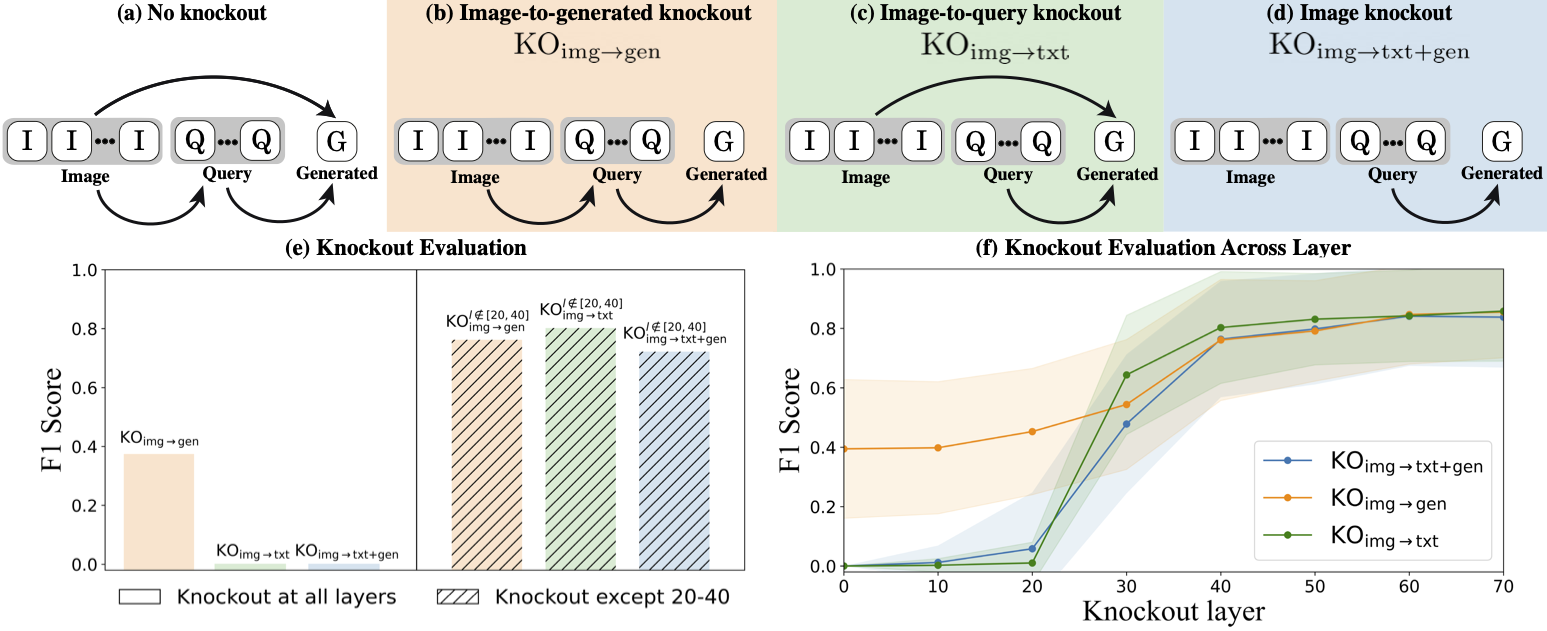
- (e) Evaluation: The performance of the model under each knockout configuration (at all layers) was measured. In the Image-to-generated configuration, the model achieved an F1 score of 0.4, demonstrating that query tokens successfully encode and relay global visual information. In contrast, the Image-to-query configuration led to a complete failure, highlighting the essential role of query tokens as global image descriptors.
- (f) Knockout from layer onward: The analysis was extended by applying knockouts starting at different layers. Results indicate a significant increase in F1 scores at the mid-layers, underscoring their critical role.
This analysis highlights the importance of query tokens in encoding global visual information and emphasizes the mid-layers' pivotal role in visual information flow.
Details localized in the mid-layers
The figure below visualizes the alignment between generated token attention to image tokens and object locations.
Pseudo ground truth object masks were obtained using SAM to validate the alignment. The peak of the attention maps, marked with a white cross, consistently matches the location of the objects in the image, demonstrating the model's ability to attend to specific visual elements.